 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum-Based Strategies for Efficient Cross-Domain Action Recognition
Jan 20, 2026Despite significant progress in human action recognition, generalizing to diverse viewpoints remains a challenge. Most existing datasets are captured from ground-level perspectives, and models trained on them often struggle to transfer to drastically different domains such as aerial views. This paper examines how curriculum-based training strategies can improve generalization to unseen real aerial-view data without using any real aerial data during training. We explore curriculum learning for cross-view action recognition using two out-of-domain sources: synthetic aerial-view data and real ground-view data. Our results on the evaluation on order of training (fine-tuning on synthetic aerial data vs. real ground data) shows that fine-tuning on real ground data but differ in how they transition from synthetic to real. The first uses a two-stage curriculum with direct fine-tuning, while the second applies a progressive curriculum that expands the dataset in multiple stages before fine-tuning. We evaluate both methods on the REMAG dataset using SlowFast (CNN-based) and MViTv2 (Transformer-based) architectures. Results show that combining the two out-of-domain datasets clearly outperforms training on a single domain, whether real ground-view or synthetic aerial-view. Both curriculum strategies match the top-1 accuracy of simple dataset combination while offering efficiency gains. With the two-step fine-tuning method, SlowFast achieves up to a 37% reduction in iterations and MViTv2 up to a 30% reduction compared to simple combination. The multi-step progressive approach further reduces iterations, by up to 9% for SlowFast and 30% for MViTv2, relative to the two-step method. These findings demonstrate that curriculum-based training can maintain comparable performance (top-1 accuracy within 3% range) while improving training efficiency in cross-view action recognition.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021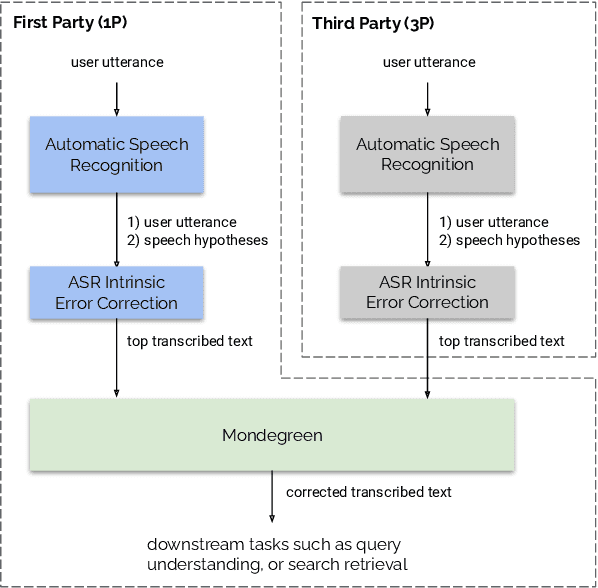
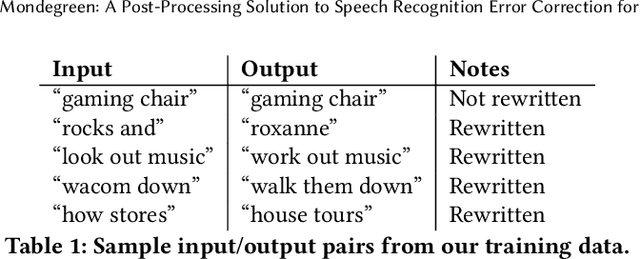
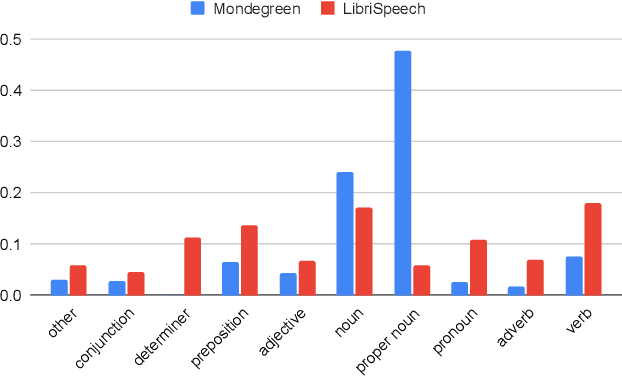
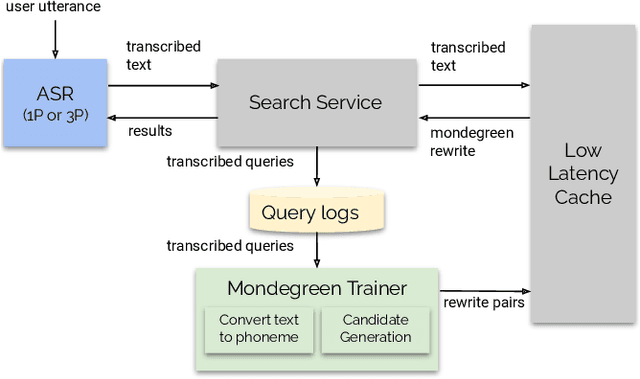
As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.
Visualizing Trends of Key Roles in News Articles
Sep 12, 2019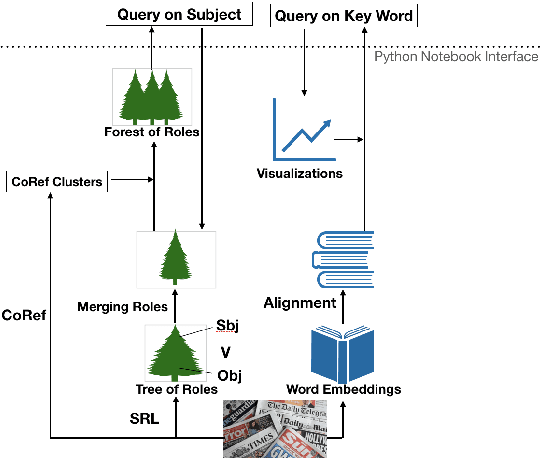



There are tons of news articles generated every day reflecting the activities of key roles such as people, organizations and political parties. Analyzing these key roles allows us to understand the trends in news. In this paper, we present a demonstration system that visualizes the trend of key roles in news articles based on natural language processing techniques. Specifically, we apply a semantic role labeler and the dynamic word embedding technique to understand relationships between key roles in the news across different time periods and visualize the trends of key role and news topics change over time.